AWS is a great place for accessing scalable, cheap resources on which to deploy data models.
However, actually using AWS for this purpose can be challenging. If you didn’t begin your project on AWS, you have to figure out a way to migrate it there. In addition, you have to determine how to handle the dataset against which you run your algorithm: should you move all of that data into AWS (and deal with the privacy challenges that this raises), just stream the data (which is not cheap), or do something else?
In this article, we’ll examine different solutions for working with data models on AWS. We’ll consider AWS’ own machine learning solutions—specifically, EMR and SageMaker—as well as the ActivePython AMI provided by ActiveState.
AWS EMR
Amazon Elastic MapReduce (EMR) was introduced in April 2009 to automate provisioning of the Hadoop cluster, run and terminate jobs, and handle data transfer between EC2 (VM) and S3 (object storage). It simplifies the management of a Hadoop cluster, making it available to anyone at the click of a button.
EMR offers several preinstalled software packages, including:
- Hadoop
- HBase
- Pig
- Hive
- Hue
- Spark, and many others.
EMR has supported Spot Instances since 2011. It is recommended that the Task Instance Group only be run on Spot Instances to take advantage of the lower cost while maintaining availability.
EMR pricing is based on the type of instances forming the cluster, and it’s divided in tiers. The pricing adds to the cost of spinning up the instances in EC2.
In addition (importantly), costs are calculated in hourly increments, so if you plan to use the cluster for two sessions of half an hour, you should have it up for one hour consecutively instead of spinning it up and down twice.
EMR is not included in the AWS free tier, so it’s always a good practice to do some price-checking before you spin up a cluster.
You can use the AWS cost calculator to estimate the cost of a three-node cluster with medium-size instances (m3.xlarge, for example), which comes out to slightly more than one dollar. If you were to keep the cluster alive for a month, that would result in a pretty high price. That’s why it’s so convenient to spin clusters up and down as they are needed.
EMR is designed to handle data transfer between Amazon EC2 and S3. It is recommended that you use these services when uploading your data. There are multiple options for getting your data from EMR to these instances, but two of the most widely used are AWS Snowball and AWS Kinesis.
AWS Snowball offers a durable and encrypted portable storage device to load streaming data into AWS. AWS will ship the device directly to you, and it can be plugged in directly to your network. Multiple devices can be used in parallel, and are configured to handle up to 50TB of data per device. Once the data is transferred into S3, or any other AWS data storage solution, the data is wiped from the Snowball device.
AWS Kinesis allows the user to capture and load streaming data into Amazon S3, or a variety of other AWS tools such as Redshift. Amazon Kinesis Firehose allows a simple API call to manage Kinesis data streams, and replaces the need to write complex code to capture and load the data. You can create the stream capture via the AWS Management Console and specify which S3 buckets you want as your destination point. Firehose also allows batching, encrypting and compressing to take place before the delivery, which is great for uptime and security.
Amazon SageMaker
AWS Re:Invent was overwhelmed with talk of automation and serverless solutions, and Amazon SageMaker is a fulfillment of that promise.
SageMaker includes hosted Jupyter notebooks and allows connections into S3, or you can utilize AWS Glue to move data from Amazon RDS, Amazon DynamoDB, and Amazon Redshift into S3 for analysis in your notebook. It is also preconfigured with TensorFlow and Apache MXNet.
More impressive is its ability to automatically tune your model, while managing all of the underlying infrastructure up to a petabyte scale. Amazon laid this process out nicely in their blog, which includes the image below, providing a quick guide on how to use the application:
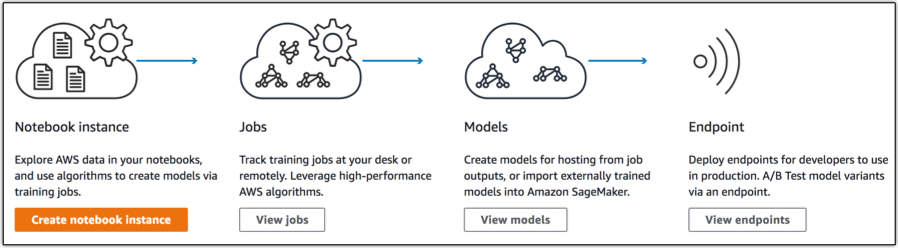 SageMaker also provides a full end-to-end workflow, allowing you to use your existing tools and/or Jupyter Notebooks that are locally stored. You can find more information on how to do this in their documentation.
SageMaker also provides a full end-to-end workflow, allowing you to use your existing tools and/or Jupyter Notebooks that are locally stored. You can find more information on how to do this in their documentation.
ActivePython AMI From ActiveState
If you have a Python algorithm to deploy on AWS, the ActivePython AMI from ActiveState is an easy-to-use solution. The AMI includes the latest versions of both Python 2.7 and 3.5, along with all the key Data Science (numpy, scipy, scikit-learn, etc) and Machine Learning packages (TensorFlow, Keras, Pandas, etc) you’ll need.
What may be the most convenient aspect of the ActivePython AMI is that it includes all the typical webdev packages as well, so you can go from creating models to implementing them in applications or services, all within the same stack.
Currently available as a private AMI, it can be run on everything from Micro to Large instances. And because the AMI is 100% compatible with the open source or ActiveState version of Python you may be running on premise, you can choose where to develop which aspects of your solution: in the enterprise or in the cloud.
Conclusion
The process for deploying machine learning algorithms is cumbersome, often ad hoc, and can be expensive for even the most frugal database administrator. However, Amazon’s focus on serverless solutions hints at a bright future and can lead to a lot fewer headaches.


