
Recently, models parameterized with trillions of words generate texts that feature not only improved context but also coherency. These advanced models pose a real challenge when it comes to detecting which content was generated by human authors versus generated artificially. Can AI detect AI-generated datasets?
In this article you will use some standard ML techniques to build a simple model to classify a text as human or artificial:
- Create an AI-generated dataset and obtain a human-generated one
- Train a classification algorithm to separate AI-generated content from human-generated, and run it
- Test the model against more advanced AI-generated content and find out if AI detects AI text
At the end, you should have a good feel for how reliable automated tools currently are when it comes to outwitting human intelligence!
Before you start: Install AI vs Humans Python Environment
To follow along, you can install the AI vs Humans Python environment for Windows or Linux, which contains Python 3.8 and all the packages you need.
In order to download this ready-to-use Python environment, you will need to create an ActiveState Platform account. Just use your GitHub credentials or your email address to register. Signing up is easy and it unlocks the ActiveState Platform’s many benefits for you!
Or you could also use our State tool to install this runtime environment.
For Windows users, run the following at a CMD prompt to automatically download and install our CLI, the State Tool along with the AI vs Humans runtime into a virtual environment:
powershell -Command "& $([scriptblock]::Create((New-Object Net.WebClient).DownloadString('https://platform.www.activestate.com/dl/cli/install.ps1'))) -activate-default Pizza-Team/AI-vs-Humans"
For Linux users, run the following to automatically download and install our CLI, the State Tool along with the AI vs Humans runtime into a virtual environment:
sh <(curl -q https://platform.www.activestate.com/dl/cli/install.sh) --activate-default Pizza-Team/AI-vs-Humans
1–Create an AI-Generated Dataset
For this task we’ll generate two datasets.
The first dataset can be generated from an existing set of short stories written by BoredHumans’s story generator, which is an online bot that uses Max Woolf’s GPT-2 (second generation “Generative Pre-trained Transformer” that is trained with only 124M hyperparameters) to create short stories. You can think of the GPT-2 model as a next word predictor. In other words, the trained data model guesses which word will be next, effectively creating a story by generating one word at a time. The language modeling behind GPT-2 also includes some techniques to try to preserve context and coherency. You can check this illustrated guide to understand the model better.
To create the dataset, we’ll just call the online bot (which is free to use) a thousand times, and then save the result as a simple CSV:
path = './data/bot_stories.csv'
async def get_bot_stories():
async with aiohttp.ClientSession() as session:
for number in range(1, 1000):
story_url = "https://boredhumans.com/api_story.php"
async with session.post(story_url) as resp:
story = await resp.text()
bot_st_file.write(str(number))
bot_st_file.write('|')
bot_st_file.write(story.replace('\n',''))
bot_st_file.write('\n')
if(os.path.isfile(path) == False):
bot_st_file = open(path,'a')
loop = asyncio.get_event_loop()
loop.run_until_complete(get_bot_stories())
Because we don’t know which sample texts were given to the BoredHumans’s story generator in order to train it, we’ll use some other random – but human-written – stories as the counterpart for this experiment. Kaggle.com has a small dataset that contains a thousand short stories taken from project Gutenberg. The file is not completely clean, but for our purposes it’s good enough:
#read the file downloaded as bot stories
df_bot = pd.read_csv('./data/bot_stories.csv', header=None, sep='|', names=['bookno','content'])
df_bot.drop_duplicates(inplace=True)
df_bot['human'] = False
#read the file from project Gutemberg
df_human = pd.read_csv('./data/stories.csv')
df_human['human'] = True
df_human.head()
#concatenate the two files
data = pd.concat( [df_bot, df_human])
data = shuffle( data )
data = data.reset_index( drop=True )
data.drop(["bookno"],axis=1,inplace=True)
data.drop_duplicates(subset=['content'])
data.dropna()
The above code snippet:
- Reads both datasets and concatenates them
- Shuffle the data
- Deletes the book number column
This will give us around two thousand stories that also contain a new column named human, which is a flag that lets us know if the story was written by a human or not.
The next code snippet applies some standard transformations in order to make it better for training our model, including:
- Converts text to lowercase
- Removes punctuation
- Removes stopwords (ie., words that don’t add much meaning to a sentence and can be safely ignored)
nltk.download('stopwords')
stop = stopwords.words('english')
data['content'] = data['content'].apply(lambda x: x.lower())
data['content'] = data['content'].str.replace('[{}]'.format(string.punctuation), '')
data['content'] = data['content'].str.replace('\n','')
data['content'] = data['content'].str.replace(start_intro,'')
data['content'] = data['content'].str.replace(end_intro, '')
data['content'] = data['content'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
2–Train a Classification Model
We will train a simple classification algorithm to determine if the texts are human-written or artificially generated. But that means we’ll need to transform the words into something we can numerically assess as part of a Logistic Regression. The simplest approach is to calculate the Term Frequency-Inverse Data Frequency (TD-IDF) score for each word in our dataset. This will produce a number for each word that represents the importance of that word in the entire dataset. Common words will have low scores, but unusual words will have higher scores, being considered more important.
This approach, although simplistic, is quick and dirty enough to generate a language model that can be used as input for a classification task. Python’s scikit-learn package provides a good TD-IDF calculator class TfidfTransformer:
pipe = Pipeline([('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('model', LogisticRegression())])
# Fitting the model
model = pipe.fit(X_train, y_train)
prediction = model.predict(X_test)
print("accuracy: {}%".format(round(accuracy_score(y_test, prediction)*100,2)))
In the above code snippet, we create a text processing pipeline which uses the CountVectorizer and the TfidfTransformer to fit a LogisticRegression model. The accuracy, with a 60/40 split of the data, is above 95%. A common approach to evaluating a classification model is to print the confusion matrix, which shows the number of correctly-labeled tests vs. incorrect ones:
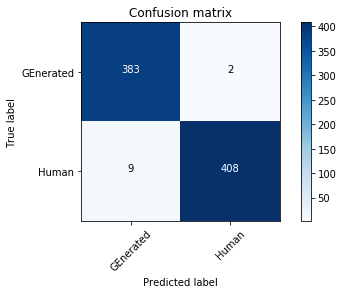
The confusion matrix shows only 11 falsely labeled samples, where:
- 9 AI-generated stories were thought to be human-generated
- 2 human-generated stories were thought to be AI-generated
These results are compelling, and clearly indicate that GPT-2 generated content is readily identifiable as machine written when compared to human written content.
3–Humans vs GPT-3
GPT-3 is the latest generation of AI for creating text-based content. Compared to GPT-2, it offers significantly advanced capabilities:
| GPT-2 | GPT-3 | |
| Parameters | 1.5 Billion | 175 Billion |
| Layers | 48 | 96 |
| Dimensional vectors | 1600 | 12,888 |
| Context window | 1024 tokens | 2048 tokens |
But better capabilities don’t necessarily translate into better results for all tasks, so let’s check our model against:
- Three real short stories taken from the website American Literature
- Three AI-generated stories that used GPT-3:
- One that was published by the Guardian
- Two from Gwern Branwen GPT-3 Creative Fiction webpage, which try to reimagine and rewrite a poem from Walt Whitman and one from John McCrae
After applying the same transformations to the texts as we previously did, we can run the classification against the new datasets:

In this case, we get 4/6 = 66% accuracy. The results are far worse than when we applied our model against GPT-2 generated content, and highlights just how far AI has come in creating much more human-like content.
Conclusions – AI Text vs Human Text
GPT models are continually advancing. GPT-2 was ten times more powerful than GPT-1 (as measured by number of parameters) when released in February 2019, and GPT-3, released just 15 months later, is 100 times more powerful than GPT-2. At this rate, AI-generated content will be indistinguishable from human content in just a few years.
But all is not lost just yet. The researchers of the Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) and IBM Research Group built the Giant Language Model Test Room (GLTR), which enables forensic analysis of AI-generated text. While not perfect, it’s word-by-word analysis gives good grounds for hope that individual texts can be reliably identified.
And as humans interacting with individual texts, we can all apply our common sense and fact-checking capabilities to prevent being fooled by this kind of content even as text generated with advanced models trained with billions of samples and hyperparameters continue to be harder to detect programmatically. Unfortunately, that has profound implications on content platforms like Twitter, Facebook, Instagram and others, which may soon be legislated to monitor content. Human monitors haven’t been able to scale to handle human-generated posts, never mind the kind of volume AI-generated posts might create. While algorithm-based content checkers will continue to be useful, they’re no silver bullet as we’ve seen with failed attempts to monitor hate speech.
- Download our AI vs Humans Python environment and see if you can create a model effective at keeping AI-generated content recognizable.
- The full code for this example is available at GitHub.
With the ActiveState Platform, you can create your Python environment in minutes, just like the one we built for this project. Try it out for yourself or learn more about how it helps Python developers be more productive.
Related Reads
Will AI Save Us? Use this Pandas Data Analysis Tutorial to find out.


