
- Creates a malware-infected open source package.
- Names the package similar to that of an existing popular package.
- Uploads it to a public repository in the hopes that developers will mistakenly download it rather than the valid package.
Unfortunately, typosquatting is incredibly effective, and has become one of the most popular ways to compromise organizations, often with the goal of extracting data.
For example, in July 2020, the Python “request” package (note the typo: request compared to the valid package name of requests) was downloaded over 10,000 times. It contained malware that installed a daemon in .bashrc, providing the attacker with a remote shell on the machine.
Compare the effectiveness of typosquatting a popular package like requests to that of pymafka, whose name is NOT based on a popular package, but was also found to contain malware:
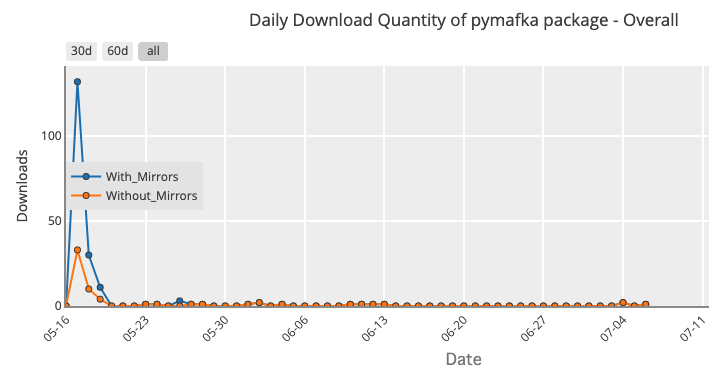
Source: pypistats.org
Clearly, typosquatting is thousands of times more effective at distributing malware, and should ideally be separately addressed as a key vector of malware infection.
In this tutorial, you will learn to create a cost-effective method for detecting typosquatted packages in the Python ecosystem, but the solution can easily be extended to any other open source language. The methodology involves:
- Determine the top 10 most downloaded packages from the Python Package Index (PyPI).
- Compare their names against other packages available on PyPI in order to find examples that differ by just a few characters.
- Create a Python routine to identify potential typosquatting instances.
- Review the results to identify packages for further investigation.
As you will see, it’s relatively easy to leverage Python’s flexibility and proven Machine Learning (ML) libraries to quickly perform what would otherwise be a very labor-intensive process.
Before You Start: Install The Typosquatting Detector Python Environment
To follow along with the code in this article, you can download and install our pre-built Typosquatting Detector environment, which contains:
- A version of Python 3.10.
- All the dependencies used in this post in a prebuilt environment for Windows, Mac and Linux.
- All the code in this post will also be installed automatically from GitHub when you install the environment.
In order to download this ready-to-use Python project, you will need to create a free ActiveState Platform account. Just use your GitHub credentials or your email address to register. Signing up is easy and it unlocks the ActiveState Platform’s many other dependency management benefits.
Or you can also use our State tool CLI to install the runtime environment and project code:
For Windows users, run the following at a CMD prompt to automatically download and install the Typosquatting Detector runtime and project code into a virtual environment:
powershell -Command "& $([scriptblock]::Create((New-Object Net.WebClient).DownloadString('https://platform.www.activestate.com/dl/cli/2080745363.1499703358_pdli01/install.ps1'))) -c'state activate --default Pizza-Team/Typosquatting-Detector'"
For Linux or Mac users, run the following to automatically download and install the Typosquatting Detector runtime and project code into a virtual environment:
sh <(curl -q https://platform.www.activestate.com/dl/cli/2080745363.1499703358_pdli01/install.sh) -c'state activate --default Pizza-Team/Typosquatting-Detector'
Step 1—Finding the Data
The beauty of a robust and open ecosystem like Python is that someone has probably created something similar to whatever you need. In this case, Hugo van Kemenade continuously generates a monthly list of the top 5,000 most downloaded packages on PyPI. I will use the first 10 entries on this list for our comparison. Currently, that list includes:
- boto3
- botocore
- urllib3
- setuptools
- requests
- s3transfer
- six
- python-dateutil
- certifi
- idna
In order to find potential instances of typosquatting, we will compare these 10 packages to the entire list of packages that are available on PyPI, which you can find in HTML format at https://pypi.org/simple/. To make things easier to work with for our purposes, I’ll use this snapshot of that list in JSON format.
Step 2—Choosing an ML Library
There are lots of ML algorithms in modern computing, and most of them are available as libraries in Python. For our purposes, we will be looking for words that are similar to those on an existing list. There are multiple ways to perform this sort of text matching, including:
- Exact matches
- Fuzzy logic (for example, for spotting double characters)
- Phonetic similarities (for example, for spotting phish vs fish)
- Checking for other minor letter/format differences using a method like Levenshtein distance.
Levenshtein distance calculates metrics based on the number of changes that it takes to get from the original string to the one you’re comparing it to. For example, the move from pythonlib to python_lib counts as one change, as does the move from meat to meet. We can use this to identify multiple ways in which typos are commonly introduced when someone is trying to typosquat on a popular framework. For our purposes, we will look at package names that are three changes away from the original name.
For this tutorial, we will use the jellyfish library, which includes Levenshtein distance among other options.
Step 3—Creating the Application
All of the code for this project can be found on GitHub. If you’ve installed the prebuilt Python 3.10 Typosquatting Detector runtime, you’ve already downloaded the project code from GitHub ready to run, but let’s review that code first.
Step A—Retrieve the JSON Files and Prepare the Data for Processing
Interacting with and retrieving JSON from an URL is a simple process, regardless of whether it’s from a static file or an API. All it takes is a few simple commands. Before we can begin, we need to import requests and JSON to enable the functionality. Then, when we request the content from the URL, it will automatically load it into an object that we can use.
First, let’s get the list of the most popular packages. Print statements are included in the code to show that it worked:
# List of top packages
top_url = requests.get("https://hugovk.github.io/top-pypi-packages/top-pypi-packages-30-days.min.json")
top_data = json.loads(top_url.text)
# How many packages in the list
print("# Records in top packages: ", len(top_data['rows']))
Next, load the second JSON file into the complete list of available packages:
# List of all packages
complete_list_url = requests.get("https://raw.githubusercontent.com/vincepower/python-pypi-package-list/main/pypi-packages.json")
complete_list_data = json.loads(complete_list_url.text)
# How many packages in the list
print("# Records in all packages: ", len(complete_list_data['packages']))
Step B—Preparing the Logic
The quickest way to compare files with the jellyfish library is to use a nested loop. That way, we can control how many of the top packages are checked, and ensure that we check them against the entire list of packages:
# How many times to loop (JSON starts counting at zero)
counter = 0
max_counter = 9
# Preparing the output
print("# The following potential names have been found")
print("# which could be typosquatting the top", max_counter+1, "packages")
print("---")
# Entering the loop for the top packages
while counter <= max_counter:
matching_list = []
# Getting the name of the next package from
# the entire list to match against
for comparing_to in complete_list_data['packages']:
# if the name matches the top entry then add it to the array to return
if top_data['rows'][counter]['project'] == comparing_to:
matching_list.append(comparing_to)
# Displaying the results of the matching
print(top_data['rows'][counter]['project'], matching_list, sep=": ")
# On to the next record in the top data
counter += 1
And that’s what our output looks like at this point. Notice that it only shows exact matches (no other potential typosquatting). To keep it easy to read, the output is formatted as YAML:
(py-env) [root@f code]# python3 main.py # Records in top packages: 5000 # Records in all packages: 385248 # The following potential names have been found # which could be typosquatting the top 10 packages --- boto3: ['boto3'] botocore: ['botocore'] urllib3: ['urllib3'] setuptools: ['setuptools'] requests: ['requests'] s3transfer: ['s3transfer'] six: ['six'] python-dateutil: ['python-dateutil'] certifi: ['certifi'] idna: ['idna']
Step C—Using the Jellyfish Library for Analysis
Now, it’s time to introduce the jellyfish library. The beauty of using existing packages is that most of the logic is handled within them. In this case, all we need to do is adjust the if statement to look beyond exact matches, and then call jellyfish with a few specific parameters:
# What Levenshtein distance are we looking for levenshtein_number = 3 # if the name is within the set number of changes # from the original then this will record it if jellyfish.levenshtein_distance(top_data['rows'][counter]['project'], comparing_to) < levenshtein_number: matching_list.append(comparing_to)
Step 4—Reviewing the Typosquatting Detection Results
As you can see, the final results identify quite a few packages that could be further investigated and potentially removed from PyPI should they be found to contain malware. The shorter package names have the most matches because it takes so few changes to end up with a completely new word. In that light, I’ve just provided a total number of returns for idna and six:
boto3: ['2to3', 'Rot13', 'Toto', 'b2tob3', 'baton', 'batou', 'bits3', 'bobo', 'bobos3', 'bobot', 'bodo', 'bogo', 'boko', 'bolos', 'boo', 'book', 'boom', 'boon', 'boooo', 'boos', 'boot', 'boron', 'boson', 'bot', 'botco', 'botcom', 'botd', 'bote', 'both', 'botlog', 'botly', 'botm', 'botnoi', 'boto', 'boto3', 'boto342', 'boto3r', 'boto4', 'botok', 'botol2', 'botol4', 'botol6', 'botool', 'botor', 'botosc', 'botouk', 'botovh', 'botox', 'botoy', 'botpy', 'bots', 'botson', 'bottom', 'bottr', 'bottt', 'botty', 'botv', 'botx', 'botxy', 'boty', 'botz', 'bouto', 'bowtor', 'bozor', 'broto', 'bto', 'coto', 'dota3', 'doto', 'foto', 'foto2', 'foton', 'goto', 'gotoh', 'hotot', 'iboto', 'koto', 'loto', 'moto', 'motoo', 'motop', 'motor', 'oto', 'pyboto3', 'roto', 'rotor', 'toto9', 'xoto3', 'yoton'] botocore: ['bob.core', 'bonecore', 'botocore', 'botocore42', 'botocove', 'kotocore'] urllib3: ['rllib', 'srllib', 'urilib', 'urllib-3', 'urllib-s3', 'urllib3', 'urllib4'] setuptools: ['nbsetuptools', 'ppsetuptools', 'sat5ptools', 'setuptls', 'setuptools', 'zetuptools'] requests: ['aquests', 'arequest', 'arequests', 'asrequests', 'crequests', 'curequests', 'dbrequests', 'drequests', 'erequests', 'fgrequests', 'frequests', 'ghrequests', 'grequests', 'jsrequests', 'mrequests', 'nbrequests', 'prequest', 'qrequest', 'reqrest', 'requesck', 'requesst', 'request2', 'requestMr', 'requestQ', 'requester', 'requestes', 'requeston', 'requestor', 'requestry', 'requests', 'requests2', 'requests3', 'requests5', 'requestsH', 'requestsWS', 'requestsaa', 'requestx', 'requestz', 'requezts', 'requrests', 'requtests', 'reqwest', 'reqwests', 'rerequests', 'torequests', 'trequests', 'txrequests', 'urequest', 'urequests', 'vrequest', 'wsrequests', 'yrequests'] s3transfer: ['eztransfer', 'iatransfer', 'qrtransfer', 's3transfer', 's3transfer42', 'sctransfer', 'transfer', 'wetransfer', 'xtransfer'] six: 1,166 matches python-dateutil: ['python-dateutil'] certifi: ['certifi', 'certifier', 'certipie', 'certipy'] idna: 266 matches
Conclusions – Extending the Typosquatting Detection Routine
As you can see, the machine learning capabilities that are now available in the Python ecosystem are quite powerful, and can provide a simple, cost-effective way to identify potential typosquatted packages before you import them into your build routine or CI/CD system.
To take things a bit further, consider the following additional checks and balances:
- Investigate the results to determine which packages are actually valid results.
- Alternatively, you could treat the entire list of packages as suspect, and check to see if they still remain in PyPI after 30 days. In most cases, compromised packages will be removed from PyPI in short order.
- Add valid package names to an exceptions file you can reference the next time you run the routine in order to remove valid packages from the results.
- Extend the routine to other ecosystems, such as JavaScript, PHP, Rust, etc
You may also want to consider adding phonetic checks to the routine, or making use of some of the other algorithms available in the jellyfish library.
Next Steps:
- You can find all of the code used in this article in my GitHub repo.
- Download the Typosquatting Detector environment and try automating your common coding tasks yourself
- Blog: Top 10 Python Packages for Machine Learning
- Blog: The Top 10 AutoML Python packages to automate your machine learning tasks
- Blog: Python’s Top 10 Machine Learning Algorithms


