
This widespread usage is enabled, in part, by an extensive standard library that offers a range of facilities designed to enhance the functionality and portability of Python. This is complemented with a growing number of packages and projects available through the Python Package Index (PyPI), which not only provide extended capabilities of Python to more domain-specific use cases, but also increase the general usability of Python. A list of the most popular packages downloaded from the Python Package Index is available here.
In this article, I’ll highlight my Top 10 packages (all of which can all be found on PyPI), and provide some basic examples of how they’re typically used.
List of Top 10 Python Packages (Popular and Useful)
Despite the many different use cases for programming in Python, there are several packages that are especially useful above all. Regardless of whether you’re using Python for ML or web apps, the following 10 packages are worth knowing and can only improve your experience with using Python. I’ll start with the absolutely necessary and end with the merely essential:
1. pip: As I discussed in a previous article, pip is the standard way of installing and managing packages in Python. Pip comes standard with every Python distribution, allowing you to accomplish installs, uninstalls, updates, etc from the command line. For example, to install a specific package with pip from PyPI, run:
| pip install “SomePackage” |
Or for a specific package version:
| pip install “SomePackage == 1.0” |
pip allows for installation from multiple sources, and is not limited to installing packages maintained on the PyPI. For more information, see the documentation here.
2. Six: Six is a Python 2 and 3 compatibility library, which is especially relevant given the amount of application migration from Python 2 to 3 organizations are currently undertaking due to Python 2’s end of life. Six reconciles the differences between Python 2 and 3, and makes adjustments based on which version is running locally. This allows Python programmers to write code that is compatible with both versions of Python, without too much difficulty.
For example, in Python 3, iterating dictionary keys is done by:
| for item in dictionary.items(): #do something |
In Python 2, iteration is done by:
| for item in dictionary.iteritems(): #do something |
With Six, the syntax is:
| import six for item in six.iteritems(dictionary): #do something |
This code will successfully run on both Python 2 and 3. Additional examples can be found in the documentation.
3. python-dateutil: The dateutil module provides a number of date and time manipulation capabilities, such as computing relative differences between two arbitrary dates, parsing datetime objects, and handling time zone information. It builds on the datetime module that is built into Python, and is simple and easy to use.
For example, to get the current local time:
| from datetime import * from dateutil.relativedelta import * now = datetime.now() |
To add an arbitrary number of months, days, and hours:
| now + relativedelta(months=1, weeks=1, hour=10) |
Or to query when the next Wednesday will occur:
| now + relativedelta(weekday=WE(+1)) |
These are just a few examples, but the general functionality follows this trend. The package is simple, but can dramatically improve your Python experience when handling time-series data. For more information, the documentation can be found here.
4. Requests: The requests package is an HTTP library for Python. It is built on top of urllib3 (another HTTP client for Python), but has a much simpler and more elegant syntax. It also integrates a few other Python libraries in order to maximize functionality while still managing to minimize complexity. Using urllib3 alone (or the built-in urllib and urllib2) allows for more customization and deeper control, but also requires more work on the side of the user. For this reason, requests is the preferred HTTP client for nearly all use cases in Python. The full list of features can be found here.
For example, here’s how to make a request to Spotify (no authentication required):
| import requests r = requests.get(‘https://api.spotify.com/’) r.status_code |
A status code in the 200’s indicates a success. From here we can extract the headers, the encoding, and a myriad of other information:
| print(r.headers) print(r.encoding) |
5. Docutils: The Documentation Utilities project exists to create a set of tools to easily process plaintext documents into more useful file formats such as HTML, XMS, or LaTeX. The project developed several front-end tools for the most common processes. This involves reading the input file (Reader tool), parsing appropriately (Parser tool), and writing the new file (Writer tool). The command line syntax for each of these tools follows a standard structure:
| toolname [options] [<source> [<destination]] |
A full list of the front-end tools can be found here. Docutils is a simple utility package with limited functionality; but necessary, considering the standard Python library does not provide any code with these capabilities.
6. Setuptools: As mentioned previously, the packages in this list are not included in the standard distribution of Python. So how does one go about distributing a third-party package? The built-in tool to do so is known as distutils, which initially established a standard methodology for bundling Python code.
As third-party packages matured, deviation from the standard occured, allowing for greater versatility and functionality in the packages themselves. The officially recommended tool to handle this is setuptools. It maintains all the functionality that distutils established, extends to third-party packages maintained on PyPI, and even those that are not. It works well with pip and other Python installation packages.
For instructions on how to create your own package, the documentation is very thorough.
The general syntax is as follows:
| from setuptools import setup setup(name=‘package_name’, version=‘0.1’, description=‘an example of a package’, url=‘http://github.com/user/example_package’, author=‘Dante’, author_email=‘dante@example.com’, license=‘MIT’, packages=[‘example’], zip_safe=False) |
7. Pytest: Testing code fidelity is not only good practice as a programmer, but is also made easy with pytest. The pytest package provides a framework to easily find bugs at any scale. It allows for parallel testing, autodetection of test functions or modules, subset testing, and other customizable features.
An example of a small test:
| # content of test_sample.py def inc(x): return x + 1 def >test_answer(): assert inc(3) == 5 |
Pytest is easily executed from the command line:
| $ pytest =========================== test session starts ============================ platform linux — Python 3.x.y, pytest-5.x.y, py-1.x.y, pluggy-0.x.y cachedir: $PYTHON_PREFIX/.pytest_cache rootdir: $REGENDOC_TMPDIR collected 1 item test_sample.py F [100%] ================================= FAILURES ================================= _______________________________ test_answer ________________________________ def test_answer(): > assert inc(3) == 5 E assert 4 == 5 E + where 4 = inc(3) test_sample.py:6: AssertionError ============================ 1 failed in 0.12s ============================= |
Additional examples can be found on the pytest website.
8. NumPy: NumPy is the essential package for scientific and mathematical computing in Python. It introduces n-dimensional arrays and matrices, which are necessary when performing sophisticated mathematical operations. It contains functions that perform basic operations on arrays, such as sorting, shaping, and other mathematical matrix operations.
For example, to create two 2×2 complex matrices and print the sum:
| import numpy as np a = np.array([[1+2j, 2+1j], [3, 4]]) b = np.array([[5, 6+6j], [7, 8+4j]]) print(a+b) |
And to take the complex conjugate of one of them:
| np.conj(a) |
More information about how NumPy is used can be found here.
9. Pandas: The pandas package introduces a novel data structure, the DataFrame, optimized for tabular, multidimensional, and heterogeneous data. Once your data has been converted to this format, the package provides intuitive and practical means to clean and manipulate it.
Manipulations such as groupby, join, merge, concatenate data or filling, replacing and imputing null values can be executed in a single line. The developers of the package have the primary goal of producing the world’s most powerful data analysis and manipulation tool that exists in any language — a daunting task that they may actually achieve.
To create a DataFrame:
| import pandas as pd df_1 = pd.DataFrame({‘col1’: [1,2], ‘col2’: [3,4]}) |
And to concatenate two dataframes together:
| df_2 = pd.DataFrame({‘col3’: [5,6], ‘col4’: [7,8]}) df = pd.concat([df_1,df_2], axis = 1) |
To perform a simple filtering operation, extracting the row that meets the logical condition:
| df[df.col3 == 5] |
Further examples can be found in the documentation here.
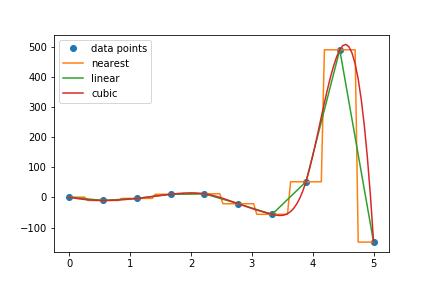
10. SciPy: The SciPy package builds on the NumPy package by providing functions and algorithms critical to scientific computation in technical fields. These are slightly more sophisticated than the operations built into NumPy, including algorithms for interpolation, optimization, clustering, transformation, and integration of data. These operations are essential when performing any type of data analysis, or developing ML-based models.
To demonstrate interpolation, I first use NumPy to create some data points with an arbitrary function, then compare different interpolation methods:
| from scipy.interpolate import interp1d import pylab x = np.linspace(0, 5, 10) y = np.exp(x) / np.cos(np.pi * x) f_nearest = interp1d(x, y, kind=‘nearest’) f_linear = interp1d(x, y) f_cubic = interp1d(x, y, kind=‘cubic’) x2 = np.linspace(0, 5, 100) pylab.plot(x, y, ‘o’, label=‘data points’) pylab.plot(x2, f_nearest(x2), label=‘nearest’) pylab.plot(x2, f_linear(x2), label=‘linear’) pylab.plot(x2, f_cubic(x2), label=‘cubic’) pylab.legend() pylab.show() |
Conclusions
If you take an objective measure of the most popular packages on PyPI by download statistics alone, you’ll get a list of packages that are quite diverse in their functionality. Some packages solely exist to improve the Python language itself, while others benefit only those who use Python for a very specific purpose, such as developing ML models or for use in conjunction with Amazon Web Services.
In contrast, the packages I’ve included in my Top 10 list are useful regardless of your use case. No matter what you use Python for, each of these packages are critical to improving your programming experience with Python, and will immediately let you become a more efficient and effective coder. Try them out and see for yourself.
All 10 packages are available on the ActiveState Platform for inclusion in your runtime environment. However, only a few (such as NumPy and SciPy) include C code. One of the key advantages of the ActiveState is it’s “build environment on demand” capabilities, allowing you to build packages that contain C code from source without the need to set up your own environment or source your own compiler. If code provenance is of value to your organization, the ActiveState platform can help lower the time and resources you spend sourcing and building your runtimes. Create a free ActiveState account and give it a try.
Fork the ‘Top 10 Python Packages” Project on Activstate’s Platform here. You get these 10 packages pre-compiled in a downloadable build!
Related Blogs:


