
The reproducibility crisis in science and technology refers to the fact that the results of many scientific studies over the past decade have been found to be difficult or even impossible to reproduce. Even well-established findings in some fields such as medicine and psychology have proven irreproducible. In practice, reproducibility involves the task of repeating the original experiment in order to obtain independent data that either corroborates or refutes the original findings. It’s one of the chief cornerstones of science, which the lack of reproducibility is starting to erode.
And it’s been going on for more than a decade. At this point, it’s begun to look like a slow-moving train wreck, analogous to the 2008 financial collapse. Sounds like hyperbole? Think of it this way:

Source: Line Goes Up – The Problem With NFTs
The diagram above shows that as the individual owners of houses defaulted on their escalating mortgage payments, the bond that assembled all of the high, medium, and low-risk mortgages into an overall “lower risk” investment vehicle that appealed to institutional investors also began to fail with far-reaching consequences, eventually triggering the 2008 collapse.
Similarly, science and technology build on top of what has come before. In science, we create new experiments based on the results of previous experiments. In technology, we create applications from the building blocks of what others have created, such as open source components. If the inputs are flawed, so are the outputs: garbage in, garbage out.
In each case, the solution is to identify and expunge the root cause in order to reestablish trust:
- In the 2008 financial crisis, the root cause was predatory lending in which lenders offered consumers mortgages with extremely low-interest rates (at least to start) in order to be able to assemble them into more and more bonds.
- In the world of science and technology, the root cause is likely a lot less insidious and may be at least partially attributable to non-reproducible software.
The Software Reproducibility Problem
Scientific experiments these days almost always involve the use of software, either in support of the experiment or to actually simulate/run the experiment itself. And this is not simplistic software. Often it’s just as complex as commercial software but typically created just for a single experiment, which can imply corner-cutting.
For example, a typical software stack for scientific experiments might be comprised of:
- Project-specific software that accomplishes the goals of the experiment. This can include scripts, APIs, workflows, computational notebooks, etc.
- Domain-specific software that includes tools and libraries which implement models and methods developed by/for specific disciplines.
- Scientific software infrastructure, which includes shared libraries and utilities used across multiple academic disciplines, such as LAPACK, NumPy, or Gnuplot, etc.
- Common software infrastructure, which includes operating systems, compilers, open source libraries, etc.
Each level builds on the software in the preceding level, creating an interdependency. As a result, a flaw at any level can negatively impact the entire stack, which can have ramifications for the experiment itself.
However, we know from our recent Software Supply Chain survey that only 22% of software organizations (on average) big and small worldwide create reproducible builds. That is, their build process is typically a one-off process run on a developer’s desktop to create the artifact(s) they need for their current project. This lack of reproducible builds has a number of ramifications, including:
- Security – the security and integrity of any built artifact are difficult to ensure since there’s no way to guarantee that the original components from which it was built weren’t compromised in the first place.
- Software – any software built on top of a non-reproducible component will itself be difficult to reproduce. This typically manifests as a proliferation of testing and debugging issues.
- Experiments – the ability to reproduce the results of experiments that make use of non-reproducible software becomes far more difficult.
So, given all these detrimental effects, why isn’t reproducibility more of a standard best practice? Cost.
The Cost of Software Reproducibility
Creating programmatically reproducible software is a non-trivial exercise. It requires:
- Operating system, programming language, compiler, etc expertise
- A dedicated (and preferably automated) build service that outputs reproducible builds by default
- Processes and policies that enforce reproducibility
All of these factors add significant overhead to any experiment/project, requiring deep-pocketed organizations to fund. This is reflected in the results of our Software Supply Chain survey, which shows that Large Enterprises (LE) are more than twice as likely to create reproducible builds than Mid-Sized Businesses (MSB) or Small & Medium Businesses (SMB):
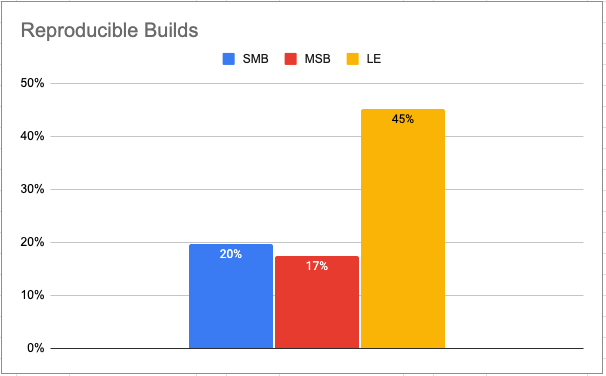
To avoid these costs, many organizations choose to implement reproducibility in more convenient ways. Chief among these solutions are:
- Virtual Machines – or VMs allow users to take a snapshot of a system at any point in time, store it, and then reboot it any time to rerun an experiment. As long as the original experiment is completely self-contained within the VM, this method affords good repeatability but fails to provide a flexible framework for iterating on the original experiment.
- Containers – provide good flexibility for reproducing and iterating on the original experiment, but suffer from bit rot. In other words, because containers are rebuilt each time they’re used, trying to replicate a container months or years later can mean that the original components/versions are no longer available, and more recent versions may not work as expected.
Looked at in this way, reproducibility becomes a trade-off between brittle, long-term replication using VMs versus flexible, short-term iteration using containers. Depending on your needs, one or the other might be appropriate, but is there a better choice?
Software Reproducibility Made Simple
If reproducibility were essentially free, we’d all be doing it already. But if it were available for a marginal cost, shouldn’t we all be at least testing it out? That’s the premise behind the ActiveState Platform: a low cost way to automatically create reproducible builds of the lower layers of your software stack. It features a secure build service that defaults to creating reproducible builds of open source languages from source code, and then bundles them into an environment you can install with a single command on your local system. In this way, reproducible builds lead to reproducible development environments, which are the foundation of reproducible code and the experiments they run.
Compared to VMs, the ActiveState Platform also offers the ability to reproduce the environment for an experiment in perpetuity since it maintains its own catalog of open source components (and all their dependencies, including OS-level dependencies) indefinitely. But unlike VMs, the environments created by the ActiveState Platform can also be modified and updated, as necessary.
Compared to containers, the ActiveState Platform also provides the flexibility to make iterations of the original experiment as required with very little overhead. But unlike typical containers, containers built with an ActiveState Platform environment are always reproducible, meaning that the original experiment can always be reproduced.
Conclusions
Reproducibility problems in the lower levels of a software stack have a domino effect, eventually compromising the reproducibility of the entire scientific experiment, and eroding trust in the academic discipline the project was seeking to bolster. But the costs associated with creating reproducible software are beyond the budget of most labs.
By leveraging the ActiveState Platform, organizations can cost-effectively achieve reproducibility and reusability with no reduction in the ability to innovate beyond the original iteration of the experiment. Combining both the longevity of VMs and the flexibility of containers, the ActiveState Platform provides a low-cost, simple-to-use solution to the software aspect of the reproducibility crisis plaguing many of the scientific disciplines today. And as an added benefit, it can also secure your open source supply chain, as well.
Next steps? Learn how to gain software reproducibility with the ActiveState Platform by getting a quick demo. Here are some useful resources to share with your team meanwhile:
- Try the ActiveState Platform for free, and see how you can take advantage of reproducible open source language environments.
- Read our Survey Report: State of Software Supply Chain Security
- Read about how to simplify environment reproducibility
Recommended Reads:
Python for Scientists and Researchers: Solving Common Problems
Reproducibility: How to Ensure Your Code Works on Every Machine


